El funcionamiento de un computador
(75 páginas)
1. Ciclo de instrucción
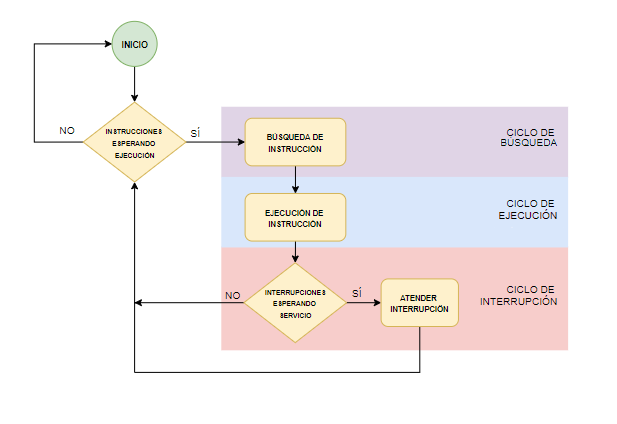
Para ejecutar instrucciones miramos si hay instrucciones disponibles. Va a una dirección de memoria concreta (Seguramente la 0) y cogerá la primera instrucción que haya allí. Acto seguido, existen dos ciclos. Dado que las instrucciones (Según la arquitectura de Von Neuman) están en memoria, en el primero, es donde se va a buscar esa instrucción, y en el otro ejecutamos dicha instrucción.
El esquema podría simplificarse si la única funcion de un computador fuera ejecutar instrucciones y sería todo lo que necesitaría un computador, independientemente del cinclo de interupción, pero un computador tambien tienen E/S, y se comunican con el computador dentro del programa, que llegan al procesardor dentro del programa.
Una interrupción detiene el flujo normal de la ejecución de instruccion.
2. Descripción interna del procesador
2.1. La memoria principal
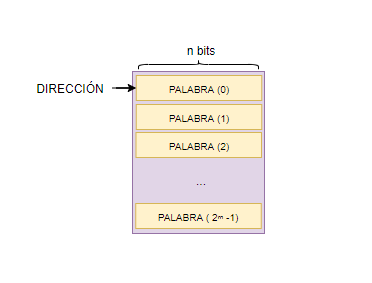
La memoria podemos definirla como una caja compuesta de otras cajas más pequeñas denominadas palabras de memoria. La memoria dispone de un espacio de direcciones, compuesto de 2ᵐ palabras diferentes, cada una de ellas de n bits.
Una dirección utilizada para designar una localización de memoria ocupa una palabra.
2.2. Los buses
Son los hilos troncales que controlan todo. Supongamos que tenemos un único bus (normalmente llamado Bus del sistema), de forma simplificada se vería algo así.
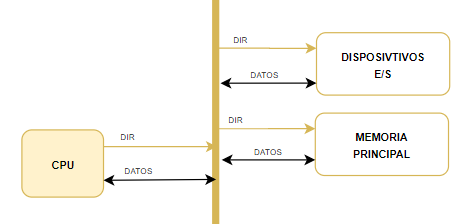
Por el bus tenemos que pasar distintos tipos de información
Bus de Direcciones, Nos sirven para determinar con qué queremos comunicarnos (donde está el dato que queremos, o bien leer o bien escribir), puede ser una dirección de un dispositivo de entrada salida, etc
Bus de Datos, La información que se va a comunicar a través del bus
Bus de Control, señales que permiten que el bus funcione adecuadamente
Los buses no tienen por qué ser medios físicos diferentes, podemos compartir las mismas líneas para los buses de información.
2.3. El camino de datos
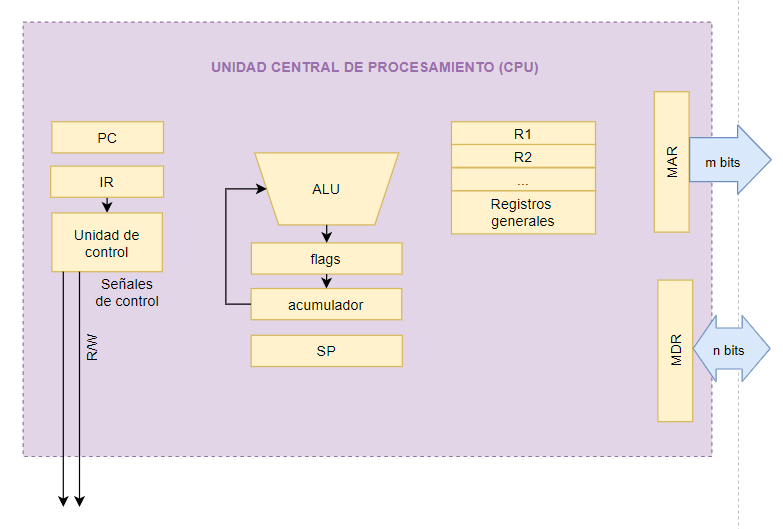
- Flags: Guardan parte del estado de la máquina, sobre todo relacionado con resultados que pueden haberse dado después de una operación en la ALU. Registra, en concreto, consecuencias de los resultados. Se interpretan bit a bit.
- Acumulador: Registro auxiliar que guarda el resultado de la ALU, para dortar de persistencia al resultado. Ya que la ALU es un circuito purmaente combinacional, no tiene posibilidad de guardar sus resultados, pero es necesario hacerlo para poder hacer uso de esos resultados desde cualquier otra parte de la máquina y no perderlo según se calcula.
- Program counter (PC): Apunta (contiene la dirección) a la siguiente instrucción a ejecutar
- Instruction Register (IR): Tiene que ver con el control de la ejecución de los programas. Es donde se almacena la primera palabra de la instrucción (opcode) en ejecución o que se va a ejecutar.
- Stack Pointer (SP): Apunta al top de la pila (una estructura de datos que se encuentra en memoria). Se hace uso de este para casos en los que se hacen llamadas a subrutinas, almacenando la dirección de la que parto para una vez ejecutada la subrutina ser capaz de volver al mismo punto del que se partió.
Subrutina: Es un fragmento de código que tiene una entrada y una salida y a la que se le puede pasar una serie de parámetros, que puede devolver o no un valor, creadas para los casos en que se tenían programas enormes y había partes que se repetía. De esta manera se guardaba el mismo código una vez, y se llamaba a este varias veces con distintos parámetros.
- Registros generales: Registros de propósito general que nos sirvan para guardar en memoria operando, para agilizar las operaciones, lugares temporales donde guardo valores normalmente de memoria antes de operarlos en la ALU. Dentro pueden haber registros arquitecturales (Registros que puede ver el programador de la máquina: R1, R2, R3..) o auxiliares (Registros a los que no se tienen acceso desde el programador).
¿Los registros que ve el programador a bajo nivel pertenecen a la arquitectura de máquina, o pertenecen a la microarquitectura/estructura?
Los registros que ve el programador pertenecen a la arquitectura. Pertenecería tambien a la estructura dependiendo de aquellos casos donde los registros arquitecturales tienen un reflejo de la estructura, un caso donde la caja física de registro tiene una correspondencia 1 a 1. Mismo nombre de regsistro. Sin embargo, hay máquinas donde no existe esa correspondencia, porque los registros aquitecturales se mapean/se ven correspondidos no por un registro físico sino, por uno dentro de un banco de registros.
- MAR (Memory Adress Register): Dirección del siguiente dato o instrucción que voy a acceder a memoria. Permite coger una dirección en el espacio de direccionamiento. No se puede direccionar más de lo que permite el MAR.
- MDR (Memory Data Register): Contiene o el dato que voy a escribir en meoria o bien le dato que acabo de leer de memoria. Cuando yo lea en memoria, lo que yo lea va a parar al MDR. El MDR es del mismo tamaño que el tamaño de palabras en memoria por lo cual cabe una palabra completa de memoria, pero eso not eiene por qué ser así.
¿Si el MAR fuer ade 2 bits? ¿A cuántas palabras de memoria diferentes podría acceder?
2² = 4 palabras. No podría acceder a palabras que estuvieran más allá de la posición 0, 1, 2 y 3.
3. Relación del camino de datos y ciclo de instrucción
-.
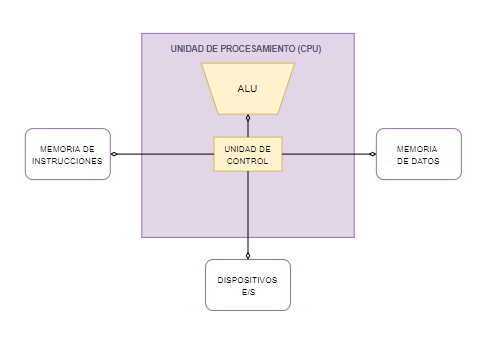
4. Otras aqrquitecturas: Harvard
Se mantiene el hecho de que el procesador esté almacenado en la memoria. La diferencia con Von Neumann es que se separa la memoria de instrucciones de la memoria de datos.
4.1 Ventajas
- Las memorias son diferentes: Pueden ser diferentes en anchura (tamaño y nº de palabras)
- Tecnologías diferentes: Memoria Volatil o No Volatil. Al no ser iguales se puede optimizar las estructuras que utilizamos para cada una de las memorias (Las formas de acceder a los datos)
- Vías de acceso sparadas a las dos memorias, lo que da la posibilidad de usarlas en paralelo
4.2 Desventajas
Para que el modelo funcione hay que ser capaz de aprovechar las dos memorias, entonces hay que asegurarse que el ritmo de uso de esta estructuras es el adecuado y está bien equilibrado, si no, el coste que se ha pagado por esa memoria no me va a revertir, entonces implica un esfuerzo para asegurarse que se usan correctamente las dos memorias en paralelo aprovechándose al máximo, sería gastar un sobrecoste en vano.
4.3 Aplicaciones
Los caché son una memoria que se integra en el procesador que trata de acceder a la memoria principal copiando partes de ella. Sabiendo esto podriamos considerar máquinas modernas hechas con Harvard, aunque no sea usual.
Se usa sobre todo en microcontroladores, procesadores digitales de señal, etc. Y normalmente, lo que se hace cuando hablamos de estructuras diferentes, por ejemplo, la memoria de instrucciones, como suele ser dispositivos de propósito específico nos encontramos con que ni siquiera es modificable. En estos casos podríamos hacer una serie de optimizaciones que no s epodrían hacer en el modelo Von Neumann.
¿En un procesador con caché separada para datos e instrucciones pero una única memoria principal seguiría siendo Von Neumann o deberíamos considerarlo una arquitectura Harvard?
No podríamos considerarla Harvard, porque para ello, tendrían que ser memorias principales separadas, una destinada a los datos y otra a las onstrucciones.
5. Instrucciones
Una instrucción es una acción elemental (atómico e indivisible) que puedes encontrar en un computador, o dicho de otro modo: Un requerimiento para realizar una determinada acción. Las instrucciones son indivisibles sólo desde el punto de vista del programador.
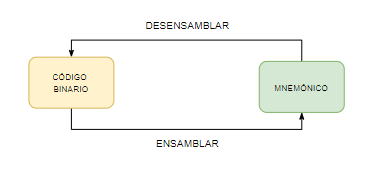
- Lenguaje máquina: Es un código binario, en lo respecto a las instrucciones, la condificación binaria de la instrucción.
- Lenguaje ensamblador: A cada instrucción biaria, le hace corresponder un nombre que lo represente para un manejo del binario menos costoso. Esos nombres de instrucciones se les conoce como mnemónicos: Secuencia de caracteres creadas para “recordarnos” cada instrucción, viene a ser similar a la filosofía de las reglas mnemotécnicas, de ahí su nombre.
En general hay una correspondencia 1 a 1. Aunque, muchos ensambladores permiten al programador hacer ciertos atajos que después de procesarse se transforman de otra manera.
¿Son muy diferentes los repertorios de instrucciones de diferentes computadores?
No son muy diferentes, es decir, no vas a encontrar un repertorio demasiado distinto en un dispositivo u otro. Pueden no ser iguales de manera exacta pero pero siempre tendrán muchas cosas en comñun (ADD o algo parecido, un MOV o algo parecido, habrá registros, direcciones de memoria), lo que se requiere de un computador va a ser siempre lo mismo en una máquina u otra.
5.1. Características
- Etiquetas/Símbolos: Permite dar nombre a las posiciones de memoria
- Declarar símbolos externos, Puntos de entrada, subrutinas o variables en otros módulos: Sirve para que luego otro programa coja el módulo objeto y que sepa de alguna forma que haya que pegar otro módulo objeto, por ejemplo en la subrutina
printf - Macros: Formas que tengo de agrupar cóigo y usarlo en más de un sitio.
Las codificaciones no pueden ser ambiguas, en el diseño de las instrucciones se debe asignar una codificación bien definida y única para cada instrucción, esto es lo que se conoce como opcode. Esto es el identificador de la intrucción, pero además, contiene detalles de como están codificados los operandos con los que fuera a trabajar dicha instrucción.
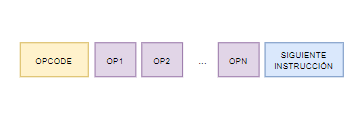
5.2. Estructura de la instrucción
La instrucción realiza una función definida, documentada por el fabricante.
Una instrucción no puede ser ambigua (su codificación debe estar bien definidia, y además, debe tener toda la información necesaria para su ejecución:
- Independientemente de su posición en memoria.
- Independiente de otras instruccipnes (Dirección de memoria real/final efctiva donde está el operando).
Se pueden categorizar las instrucciones de varias formas (Clasificación de los repertorios)
- Según el numero de operandos con los que trabaja la isntrucción
M. de 3 direcciones: ADD R1, R2, R3 (R1 <- R2 + R3)
M. de 2 direcciones: ADD R1, R2 (R1 <- R2 + R1)
M. de 1 dirección : ADD R1 (ACC <- ACC + R1)
M. de 0 direcciones: ADD (<tope de pila> <- <tope> + <tope-1>)
- Según el número máximo de operandos de memoria que usa la ALU
Arquitectura registro-registro (0/3 operandos de memoria)
Arquitectura registro-memoria (1/2 operandos de memoria)
Arquitectura memoria-memoria (2/2 o 3/3 operandos de memoria)
- Según el número máximo de operandos de memoria que usa la ALU
Fija: Se dedica un numero finito y determinado a un juego de instrucciones
Variable: Permiten añadir dinamicmente más instrucciones. Un opcode es prefijo de otro.
¿Si tengo un repertorio grande de instrucciones, que tenga 8 operaciones cuántos bits necesito para codificar ese repertorio?
8 = 2³, por tanto encesitaríamos 3 bits.
5.3. Optimizando el juego de instrucciones
Condiciones deseables de una codificación. Las dimensiones en las que se puede en focar para optimizar el jeugo de instrucciones es.
- Completitud: Capacidad de implementar cualquier función (sumas, saltos, movimiento de datos)
- Eficiencia: Las instrucciones más eficientes son las más rápidas.
- Regularidad: Existir simetría en los opcodes (Posibilidad de combinar los diferentes operandos en las instrucciones)
- Compatibilidad: Es preferible expandir las funcionalidades de cualquier ISA a carecer compatibilidad con ellas.
¿Son mejores las instrucciones cortas o largas?
Que sean cortas hace que sean más rapidas de leer, sencillas de procesar/codificar, ocupan menos memoria. Las largas facilitan el trabajo del programador, ya que con menos pasos podría hacer lo mismo.
5.4. Tipos

6. Técnicas de codificación del opcode con longitud variable
En ambas codificaciones conocidas, ningún opcode puede ser prefijo de otro.
6.1. Codificación por expansión
Queremos construir un repertorio con las siguientes características:
15 instrucciones de 6 operandos
14 instrucciones de 2 operandos
31 instrucciones de 1 operando
16 instrucciones de 0 operandosTenemos:
16 registros, y sólo operamos con los registros en las instrucciones (4 bits por operando)
Arranco desde el opcode (0000) hasta 15-1 (1110)
(15 instrucciones de 3 operandos)
opde OP1 OP2 OP3
————————————————————
0000 XXXX YYYY ZZZZ
0001
... (+14)
1110
Arranco desde el opcode (1111 0000) hasta 14-1 (… 1101)
(14 instrucciones de 2 operandos)
opde OP1 OP2
———————————————————
1111 0000 YYYY ZZZZ
... (+13)
1111 1101
Arranco desde el opcode (1111 1110 0000) hasta 31-1 (16+14)
(31 instrucciones de 1 operando)
opde OP1
———————————————————
1111 1110 0000 ZZZZ
... (+16)
1111 1110 1111 ZZZZ
1111 1111 0000 ZZZZ (+1)
... (+13)
1111 1111 1110 ZZZZ
Arranco desde el opcode (1111 1111 1111 0000) hasta 16-1 (1111)
(16 instrucciones de 0 operando)
opde
———————————————————
1111 1111 1111 0000
... (+16)
1111 1110 1111 1111
6.2. Codificación Huffman
Tener opcodes más cortos abarata en tiempo el coste la decodificación de los opcodes, por esto se utiliza la codificación Huffman, se asigna opcodes más cortos a instrucciones más frecuentes. A la larga se consigue que sea más rápido decodiifcar las instrucciones y aparte, así, los programas ocupan menos en memoria.
Queremos construir un repertorio de 8 instrucciones cada una con las siguientes frecuencias relativas:
| Instrucción | frecuencia |
|---|---|
| LOAD | 0,25 |
| STORE | 0,25 |
| ADD | 0,125 |
| AND | 0,125 |
| NOT | 0,0625 |
| RSHIFT | 0,0625 |
| JUMP | 0,0625 |
| HALT | 0,0625 |
- Construir la tabla de instrucciones en orden decreciente por frecuencia
- Sumar las dos ultimas posiciones y reordenar el resultado sin perder de vista de dónde vino (repetir hasta tener 2 elementos)

- Comenzar la marcha atrás. (Repetir hasta volver al principio)
- Si una frecuencia venía de la suma de otros dos, añadir un nuevo bit a la codificación de la instrucción
- Si no, dejar el código como está

7. Modos de direccionamiento
Indica el procedimiento por el que yo puedo acceder a un operando. Se define como la accion que utilizamos para especificar el modo de uso de un operando en una instrucción, y además, define la forma de cómo accedemos a los operandos, es decir la descripción del método para llegar a dicho operando.
Permiten utilizar las codificaciones más sintéticas que oucupen menos espacio para acceder a un mayor espacio de direcciones y simplificar el acceso a estructiras complejas de memoria.
7.1. Notación
A, B... : Campo de dirección de memoria en la instrucción (dirección contenida en la propia instrucción).
Rₓ : Campo de "dirección" de registro en la instrucción
EA : Dirección efectiva
D, #Inm : Constante inmediata
(x) : Contenido de la posición en memoria x o indirección. El simil de los punteros a bajo nivel.
[] : Indexación.
7.2. Direccionamiento inmediato
El operando está en la propia inrucción.

7.3. Direccionamiento directo de registro y de memoria
Un campo de direcciones (registros o memoria) contiene la dirección del operando.
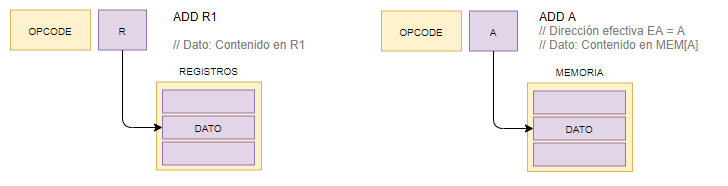
No conviene abusar a menos que vayan a usarse operaciones sobre el mismo registro.
8.4. Direccionamiento indirecto de registro y de memoria
Existe para poder dotar de mayor flexibildad al programa ante una perspectiva en la que solo se podían manejar variables globales o estáticas. Es más eficiene el direccionamiento indirecto de registro porque el de memoria implica acceder dos veces a memoria, y acceder a memoria resulta más costoso que obtener la dirección del dato desde un registro que ya se encuentra en la CPU, (menos caminoa recorrer, menos costo).
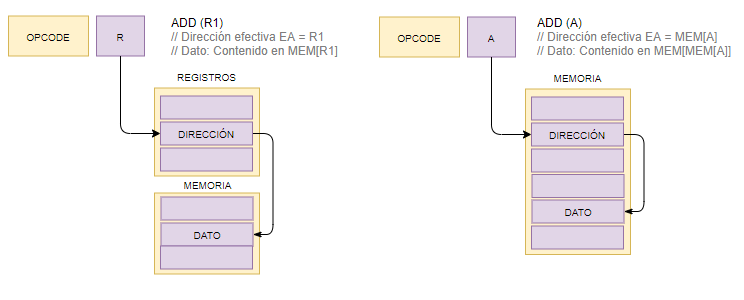
Permite el paso por referencia a subrutinas
7.5. Direccionamiento relativo o con desplazamiento
Permite reubicación de programas.
7.5.1 Relativo a Program Counter
La dirección base es el PC y el desplazamiento es una constante en cpl2 (con signo).
Se trata de un salto relativo a la dirección del programa.
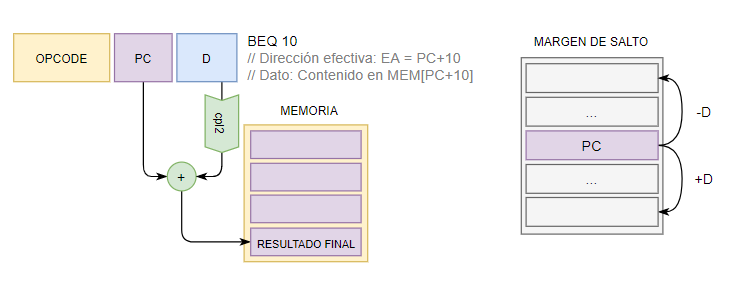
7.5.1 Relativo a Registro base
La dirección base la contiene un Registro y el desplazamiento es una constante (sin signo). Su filosofía es como el acceso a la posición de un array.
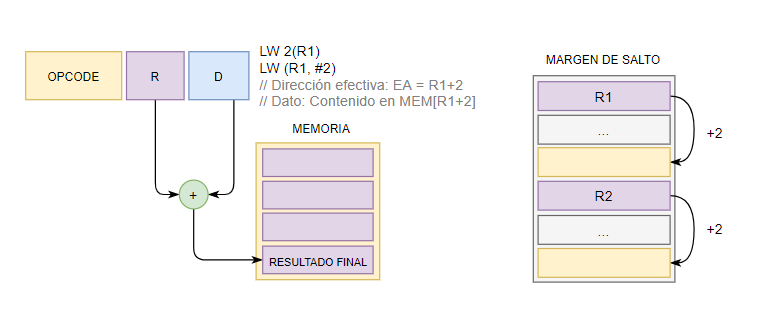
7.5.2 Indexado
La dirección base la contiene una dirección de Memoria y el desplazamiento es un Registro que hace de índice. Como el desplazamiento es mutable, puede entenderse como los índices de un loop, que vayan incrementando en un recorrido.
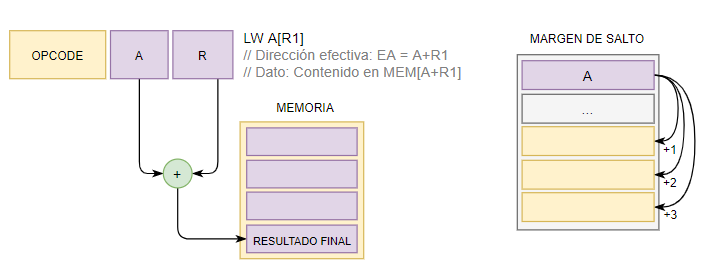
7.6. Direccionamiento de pila
Direccionamiento implicito.

Permite instrucciones muy compactas.
En máquinas especiales suele estar muy optimizado
8. Computadores
8.1. Rendimeinto de un computador
¿Qué hace un computador mejor que otro?
La velocidad, la eficiencia, el número de operaciones por minuto, el throughput/rendimiento, capacidad (más memoria, más disco duro), coste, consumo energético, tamaño robuste, durabilidad…
8.2. Tipos de computadores
| Computador | Coste | Consumo energético | Rendimiento computacional | Tamaño |
| Microcontrolador | ▉▉ | ▉▉▉ | ▉ | ▉▉▉ |
| SoC | ▉▉▎ | ▉▉▎ | ▉▉▎ | ▉▉ |
| PC | ▉ | ▉ | ▉▉▉ | ▉ |
| Portátil | ▉ | ▉▉ | ▉▉▎ | ▉▉▎ |
| Servidor | ▉ | ▉▉▉ | ▉▉▉ | ▉ |
| Máquina de cómputo científico | ▎ | ▉▉ | ▉▉▉▉ | ▎ |
9. Mejoras del rendimiento computacional
Debido a que los límites de la explotación del rendimiento en el hardware está llegando a su tope, la mejor forma de sacar partido de éstos es el de conseguir ejecutar procesos en paralelo (paralelismo)
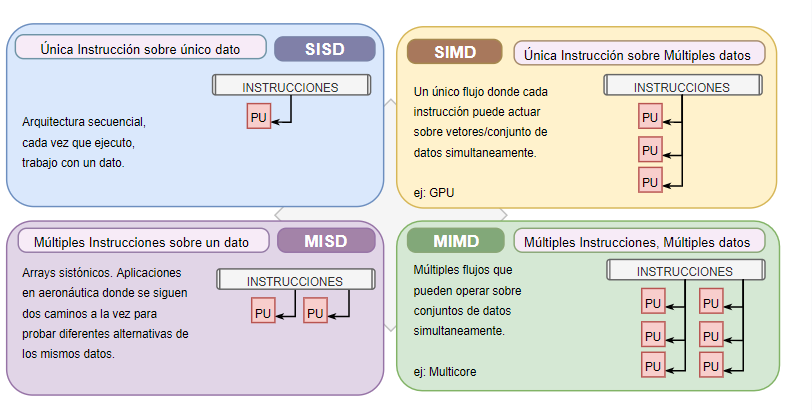
Fynn: Por cada flujo podemos tener un único flujo (S) o múltiples (M) donde el programa se puede resolver en varios flujos que intercambian información entre sí, y ambos pueden ser de instrucciones (I) o de datos (D)..
El flujo de datos/información se refiere acerca del movimiento que tienen los datos en el sistema. Pueden representar a los distintos hilos de procesamiento, o las tareas que se ejecutan en paralelo si hay varios flujos ejecutándose a la vez.
Rendiemento = Nºintrucciones/programa * CPI * tiempo
13.1. Clasificación de Flynn
13.2. Paralelismo potencial en aplicaciones
- Paralelismo a nivel de datos: El símil de SIMD.
- Paralelismo a nivel de tareas: Multiples treas/procesos en paralelo.
13.3. Paralelismo en el hardware
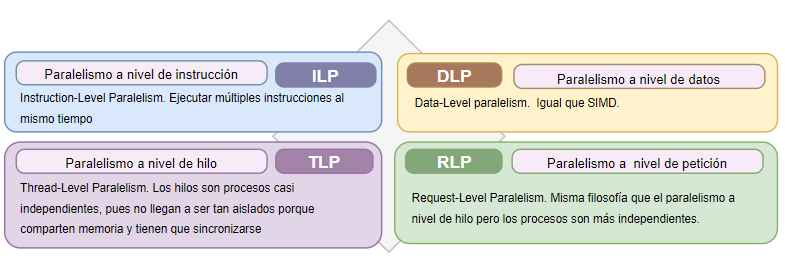
14 Paralelismo a nivel de instrucción (MI/ILP)
¿En qué cosas debería fijarme para explotar el paralelismo a nivel de instrucción?
- Determinar la dependencia entre las instrucciones.
- Duplicar/adecuar los recursos del hardware de modo que sea posible ejecutar un número de procesos en paralelo.
- Diseñar estrategias que permitan determinar cuándo una instrucción está lista para ejecutarse.
- Diseñar técnicas para pasar valores de una a otra instrucción.
14.1. Segmentación
Es una forma de explotar el paralelismo en un computador. Funciona similar a una cadena de montaje
- Todas las instrucciones atraviesan todas las etapas
- Dos etapas diferentes no comparten recursos
- La latencia o tiempo de propagación de una etapa a la siguiente es siempre igual
- Lo que ocurre con una instrucción en una etapa no debe depender de lo que ocurra con otras instrucciones en otras etapas.
¿La segmentación reduce el tiempo de ejecución de una instrucción?
No lo reduce, normalmente lo aumenta debido a las etapas más lentas. No mejora el tiempo de ejecución de la instrucción, mejora la medida de throughput (rendimiento) que corresponde al número de instrucciones que se sacan por ciclo.
Dicho de otro modo. No está pensado para mejorar el tiempo de una instrucción, sino para mejorar el tiempo de muchas instrucciones.
¿De qué otra forma se puede mejorar más aún el rendimiento de ILP, más allá de la segementación?
Lanzar más de una instrucción por ciclo, se duplica/aumenta, así la pipeline (tecnica de visión múltiple de instrucciones)
Para lanzar más de una instrucción por ciclo hay que hacer una planificación para determinar las instrucciones que se pueden lanzar a la vez.

Según la aproximación más cercana al Hardware, sería éste quien se encargaría de decidir en cada momento si un numero N de instrucciones se pueden ejecutar a la vez o no, mirando si hay dependencias en las instrucciones, si el recurso está disponible para ejecutar. SU ejemplo serían las máquinas superescalares.
Según la aproximación cercana al software, es el compilador el que decide. Analiza el código y estáticamente planifica qué instrucción se puede ejecutar creando paquetes de instrucciones.
- Existe el caso en las que interviene instrucciones muy largas, que corresponde a los recursos del hardware del sistema y el ejemplo de máquinas que usan esto son las VLIW (Very Low Instruction Word)
- Similar a esto, pero más sofisticado, existe EPIC que usa paquetes de isntrucciones, más flexible y no es tan dependiente del hardware. El problema es esto es que no puede adaptarse a los cambios de la máquina.
15. Paralelismo a nivel de hilo/thread (MI/TLP)
Partir el núcleo en núcleos más pequeños. Dividir la ejecución, planificicarlo para que la ejeción funcione en múltiples hilos.
- Múltiples procesadores: Se puede tener un ordenador con varios procesadores en la placa madre, aunque no es lo más habitual
- Un procesador con múltiples núcleos: Es más habitual tener múltiples núclos en un chip.
- Un sólo núcleo: Varios Program Counter (PC).
15.1. Multithreading por bloque/reparto de tiempo
Se pueden utilizar sobre un único procesador. Consiste en intercalar la ejecuciónd e hilos. Tiene dos vertientes (Cada hilo tendrá su estado arquitectural):
- Grano grueso: La UC conmuta entre hilos solo en caso de largas demoras/entorpecimientos, como fallos de caché.
- Grano fino: La UC conmuta entre hilos en cada instrucción, entrelazando la ejecución de los diferentes hilos. Su exigencia de hardware es mayor.
15.2. Simultaneus Multithreading (SMT)
Los recursos internos estarían duplicados/replicados (ALU, decodificadores..). Estados de arranque. Ejecución paralela de varios hilos
16. Paralelismo a nivel de datos (MD/DLP)
Cada dato recibe la acción de la instriccón. Muchas arquitecturas lo incluyen, como intel (MMX, SSE, AVX..), trabajan con datos vectoriales, lo que suponen registrso de 128 bits como si fueran vectores.
Existen otros modelos como las GPU, no trabajan con datos vectoriales, sino que se trabaja con muchos núcleos, lo que supone una tendencia a trabajar como el TLP. Lo que, si los nucleos tienen restricciones para que mantengan un sincronismo y se enfoquen en los datos del mismo programa, estaría funcionando a nivel de MD.